Object Cache
Object cache refers to mapping id to entity object. This is the simplest and most basic cache.
Enabling Object Caching
- Java
- Kotlin
@Bean
public CacheFactory cacheFactory(
RedisConnectionFactory connectionFactory,
ObjectMapper objectMapper
) {
return new CacheFactory() {
@Override
public Cache<?, ?> createObjectCache(@NotNull ImmutableType type) {
return new ChainCacheBuilder<>()
.add(
CaffeineValueBinder
.forObject(type)
.maximumSize(1024)
.duration(Duration.ofHours(1))
.build()
)
.add(
RedisValueBinder
.forObject(type)
.redis(connectionFactory)
.objectMapper(objectMapper)
.duration(Duration.ofHours(24))
.build()
)
.build();
}
...omit other code...
};
}
@Bean
fun cacheFactory(
connectionFactory: RedisConnectionFactory,
objectMapper: ObjectMapper
): KCacheFactory {
return object: KCacheFactory {
override fun createObjectCache(type: ImmutableType): Cache<*, *>? =
ChainCacheBuilder<Any, Any>()
.add(
CaffeineValueBinder
.forObject(type)
.maximumSize(1024)
.duration(Duration.ofHours(1))
.build()
)
.add(
RedisValueBinder
.forObject(type)
.redis(connectionFactory)
.objectMapper(objectMapper)
.duration(Duration.ofHours(24))
.build()
)
.build()
...omit other code...
}
}
If you don't want to support object cache for some entity types, just return null.
- Java
- Kotlin
@Override
public Cache<?, ?> createObjectCache(ImmutableType type) {
if (type.getJavaClass() == SomeEntity.class) {
return null;
}
...
}
override fun createObjectCache(type: ImmutableType): Cache<*, *>? =
if (type.javaClass === SomeEntity::class.java) {
null
} else {
...
}
Using Object Cache
There are two usage patterns that can utilize the object cache:
-
Query entity objects (or their collections) by id (or their collections)
-
Use object fetchers to fetch any non-id fields of associated objects
Query Based on Id
- Java
- Kotlin
Map<Long, Book> bookMap = sqlClient.findMapByIds(
Book.class,
Arrays.asList(1L, 2L, 3L, 4L, 999L)
);
System.out.println(bookMap);
val bookMap = sqlClient.findMapByIds(
Book::class,
listOf(1L, 2L, 3L, 4L, 999L)
)
println(bookMap)
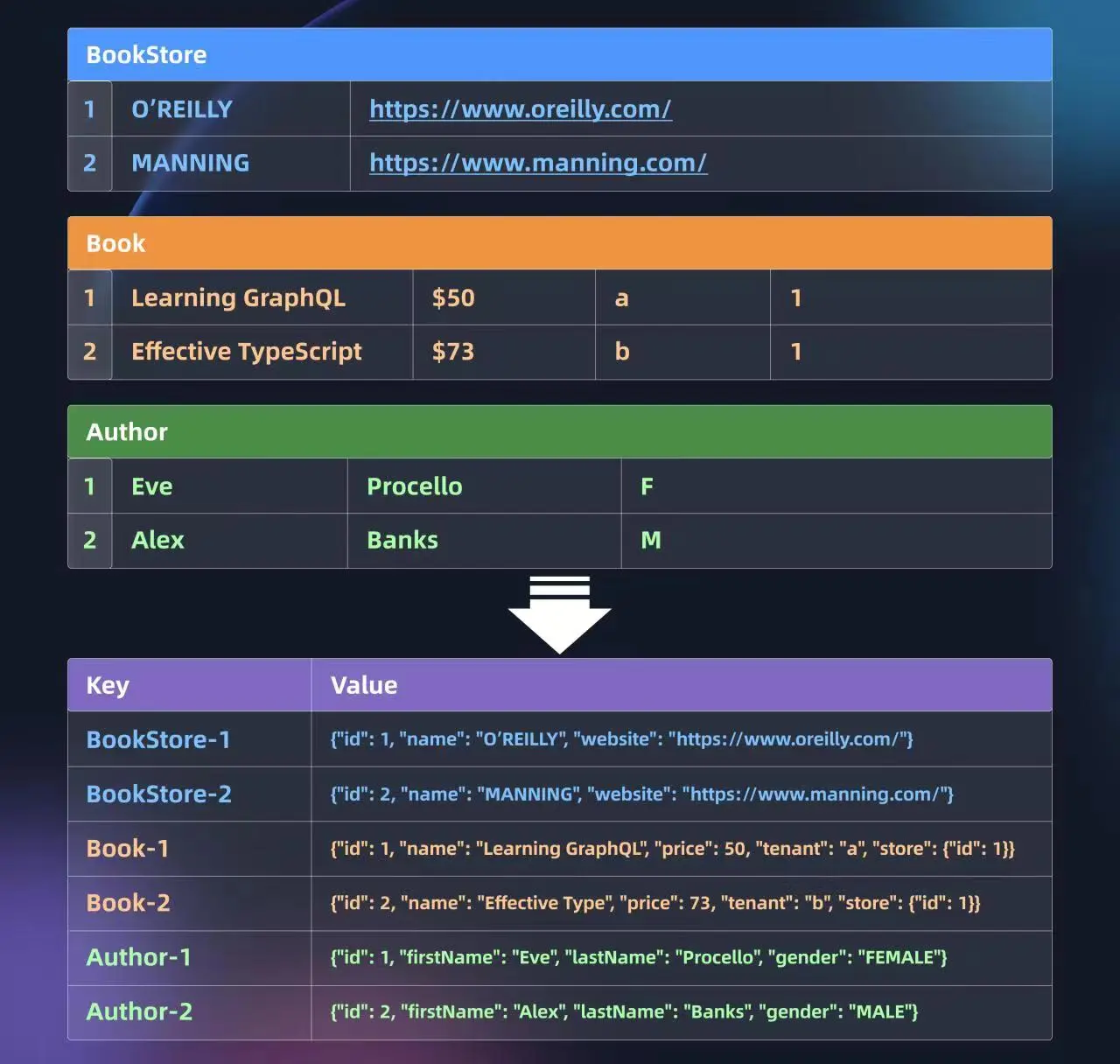
Jimmer first looks up the data in the cache with keys Book-1, Book-2, Book-3, Book-4 and Book-999.
Suppose the data corresponding to these keys cannot be found in the cache:
127.0.0.1:6379> keys Book-*
(empty array)
So the following SQL is executed to load data from the database:
select
tb_1_.ID,
tb_1_.NAME,
tb_1_.EDITION,
tb_1_.PRICE,
tb_1_.STORE_ID
from BOOK tb_1_
where
tb_1_.ID in (
? /* 1 */, ? /* 2 */, ? /* 3 */, ? /* 4 */, ? /* 999 */
)
Jimmer will put the query results into the cache, so we can view this data in the cache:
127.0.0.1:6379> keys Book-*
1) "Book-4"
2) "Book-2"
3) "Book-3"
4) "Book-1"
5) "Book-999"
127.0.0.1:6379> get Book-1
"{\"id\":1,\"name\":\"Learning GraphQL\",\"edition\":1,\"price\":50.00,\"store\":{\"id\":1}}"
127.0.0.1:6379> get Book-2
"{\"id\":2,\"name\":\"Learning GraphQL\",\"edition\":2,\"price\":55.00,\"store\":{\"id\":1}}"
127.0.0.1:6379> get Book-3
"{\"id\":3,\"name\":\"Learning GraphQL\",\"edition\":3,\"price\":51.00,\"store\":{\"id\":1}}"
127.0.0.1:6379> get Book-4
"{\"id\":4,\"name\":\"Effective TypeScript\",\"edition\":1,\"price\":73.00,\"store\":{\"id\":1}}"
127.0.0.1:6379> get Book-999
"<null>"
127.0.0.1:6379>
The non-existent data Book-999 is also cached with the special value <null>.
Undoubtedly, before the data in the cache expires, executing the Java/Kotlin code above again will directly return the data from the cache without any SQL being generated.
Using Object Fetchers
- Java
- Kotlin
BookTable table = Tables.BOOK_TABLE;
List<Book> books = sqlClient
.createQuery(table)
.where(table.name().like("GraphQL"))
.select(
table.fetch(
Fetchers.BOOK_FETCHER
.allScalarFields()
.store(
Fetchers.BOOK_STORE_FETCHER
.name()
)
)
)
.execute();
System.out.println(books);
val books = sqlClient
.createQuery(Book::class) {
where(table.name like "GraphQL")
select(
table.fetchBy {
allScalarFields()
store {
name()
}
}
)
}
.execute()
println(books)
-
1st SQL: Query aggregate root
First, query the aggregate root object, executing the following SQL:
select
tb_1_.ID,
tb_1_.NAME,
tb_1_.EDITION,
tb_1_.PRICE,
tb_1_.STORE_ID
from BOOK tb_1_
where
tb_1_.NAME like ? /* %GraphQL% */The fuzzy query in the code is implemented here to obtain some Book objects. Such objects obtained by direct user queries are called aggregate root objects.
cautionJimmer does not cache aggregate objects returned by user queries, because the consistency of such query results cannot be guaranteed.
Even if cache them at the cost of sacrificing consistency is required, it is a business need of the user rather than the framework.
-
2nd SQL: Fetch many-to-one association
Book.storeThe above code will return a series of aggregate root objects. If using the official sample data in the database, it will return 6 aggregate root objects.
The object fetcher in the code contains the many-to-one association
Book.storeand expects to query non-id properties of the associated object (information that cannot be expressed by the foreign key of the current table), so Jimmer will query the associated object for all aggregate root objects.Fortunately, the associated attribute
Book.storeis based on a real foreign key. The foreign key itself represents the id of the parent object. There is no need to obtain the associated object id through additional queries or association cache.Suppose the foreign key
STORE_IDof the 6 BOOK data has two distinct values after deduplication, 1 and 2.Jimmer first looks up the data in the cache with keys
BookStore-1andBookStore-2.Suppose the data corresponding to these keys cannot be found in the cache:
127.0.0.1:6379> keys BookStore-*
(empty array)Then the following SQL is executed to load data from the database:
select
tb_1_.ID,
tb_1_.NAME,
tb_1_.WEBSITE
from BOOK_STORE tb_1_
where
tb_1_.ID in (
? /* 1 */, ? /* 2 */
)infoWe only need the
IDandNAMEfields, but here all fields are queried, which is different from what was discussed earlier in Object Fetcher. Please view:Jimmer will put the query results into the cache, so we can view this data in the cache:
127.0.0.1:6379> keys BookStore-*
1) "BookStore-1"
2) "BookStore-2"
127.0.0.1:6379> get BookStore-1
"{\"id\":1,\"name\":\"O'REILLY\",\"website\":null}"
127.0.0.1:6379> get BookStore-2
"{\"id\":2,\"name\":\"MANNING\",\"website\":null}"
127.0.0.1:6379>Undoubtedly, before the data in the cache expires, executing the Java/Kotlin code above again will directly return the associated data from the cache without generating the 2nd SQL statement.
Finally, Jimmer concatenates the results of the two steps as the final data returned to the user:
[
{
"id":1,
"name":"Learning GraphQL",
"edition":1,
"price":50,
"store":{
"id":1,
"name":"O'REILLY"
}
},
{
...omit...
},
{
...omit...
},
{
"id":10,
"name":"GraphQL in Action",
"edition":1,
"price":80,
"store":{
"id":2,
"name":"MANNING"
}
},
{
...omit...
},
{
...omit...
}
]
Cache Invalidation
To use Jimmer's automatic cache invalidation, triggers need to be enabled first.
-
If BinLog trigger is enabled, modifying the database by any means can lead to Jimmer's cache consistency intervention. For example, directly execute the following SQL in the SQL IDE:
update BOOK_STORE
set WEBSITE = 'https://www.manning.com'
where ID = 2; -
If only Transaction trigger is enabled, Jimmer's API must be used to modify the database:
- Java
- Kotlin
BookStoreTable table = Tables.BOOK_STORE_TABLE;
sqlClient
.createUpdate(table)
.set(table.website(), "https://www.manning.com")
.where(table.id().eq(2L))
.execute();sqlClient
.createUpdate(BookStore::class) {
set(table.website, "https://www.manning.com")
where(table.id eq 2L)
}
.execute()
Regardless of which way above is used to modify the data, you will see the following log output:
Delete data from redis: [BookStore-2]