Association Cache
Association cache refers to mapping the current object id to the associated object id or collection.
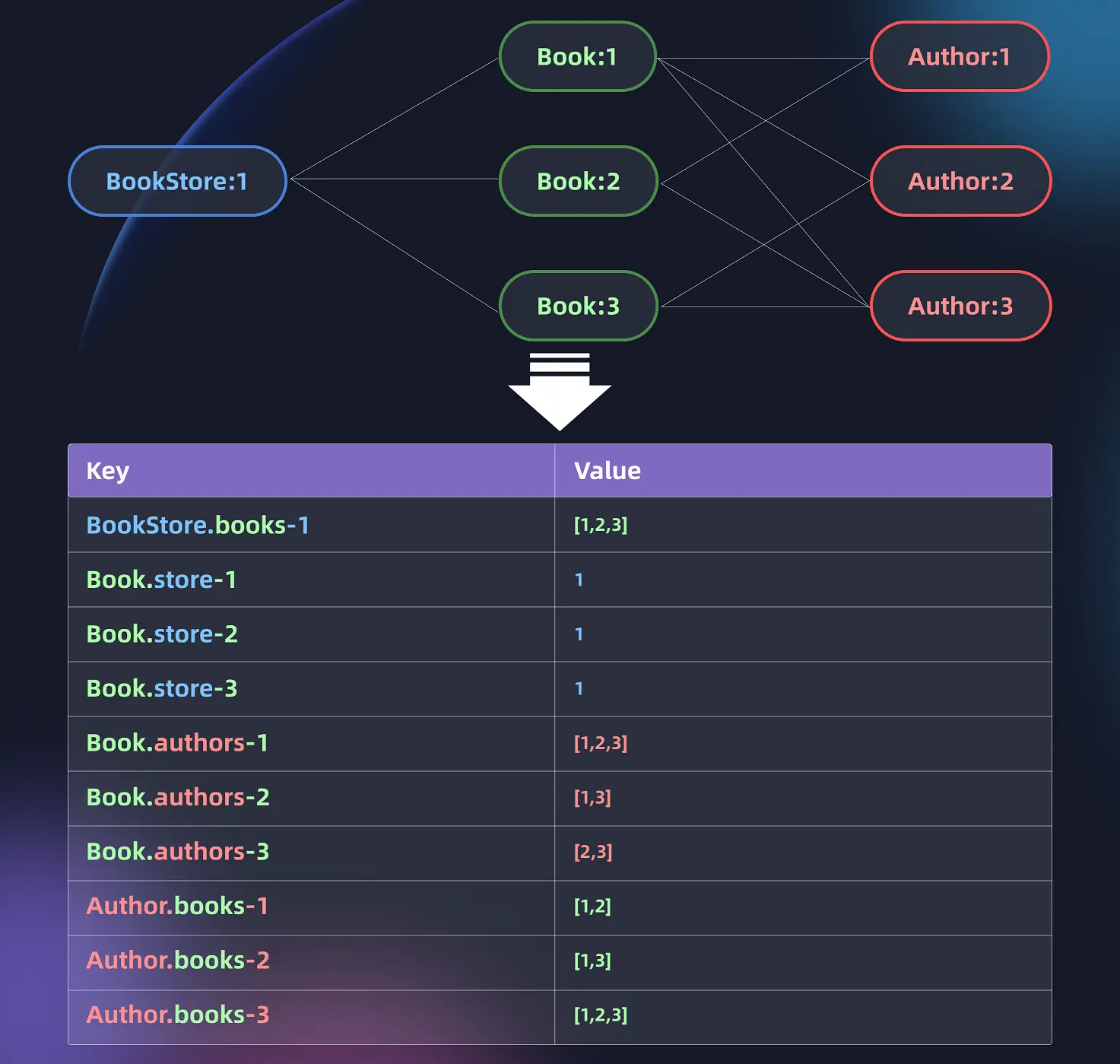
Where:
BookStore.books-*: One-to-many association cacheBook.store-*: Many-to-one association cacheBook.authors-*: Many-to-many association cacheAuthor.books-*: Many-to-many association cache
Unlike other association caches, there is one scenario that does not require using one-to-one or many-to-one association cache.
If a one-to-one or many-to-one association is based on a real foreign key with a corresponding foreign key constraint in the database, then the foreign key itself is the associated object id, and association cache is not required.
In other cases, Jimmer will use one-to-one or many-to-one association cache. These cases include:
-
The referenced association property is reverse side
That is,
@OneToOne'smappedByis configured. -
The referenced association property is based on a pseudo foreign key
A pseudo foreign key means that it is conceptually a foreign key in the developer's mind, but there is no corresponding foreign key constraint in the database.
The pseudo foreign key field may contain illegal values, the non-null value does not mean the associated object exists, so association cache is required to filter out valid associated objects.
-
The referenced association property is based on a join table rather than a foreign key.
-
When implementing GraphQL with Jimmer, Object Fetcher (GraphQL and Object Fetchers are homogenous functions) should not be used in aggregate root queries, but object fetcher were incorrectly used in aggregate root queries to obtain objects without foreign keys. However, the GraphQL request body contains many-to-one associations.
In the official sample code included, the many-to-one association Book.store is based on a real foreign key, so its many-to-one cache will not be used.
Therefore, the examples in this article use the one-to-many association BookStore.books and the many-to-many association Book.authors.
Enabling Association Cache
- Java
- Kotlin
@Bean
public CacheFactory cacheFactory(
RedisConnectionFactory connectionFactory,
ObjectMapper objectMapper
) {
return new CacheFactory() {
@Override
public Cache<?, ?> createObjectCache(@NotNull ImmutableType type) {
...omit code...
}
// Map current object id to associated object id
// Applies to one-to-one and many-to-one associations
@Override
public Cache<?, ?> createAssociatedIdCache(@NotNull ImmutableProp prop) {
return createPropCache(
prop,
Duration.ofMinutes(10),
Duration.ofHours(10)
);
}
// Map current object id to collection of associated object ids
// Applies to one-to-many and many-to-many associations
@Override
public Cache<?, List<?>> createAssociatedIdListCache(@NotNull ImmutableProp prop) {
return createPropCache(
prop,
Duration.ofMinutes(5),
Duration.ofHours(5)
);
}
private <K, V> Cache<K, V> createPropCache(
ImmutableProp prop,
Duration caffeineDuration,
Duration redisDuration
) {
return new ChainCacheBuilder<>()
.add(
CaffeineValueBinder
.forObject(type)
.maximumSize(512)
.duration(caffeineDuration)
.build()
)
.add(
RedisValueBinder
.forProp(prop)
.redis(connectionFactory)
.objectMapper(objectMapper)
.duration(redisDuration)
.build()
)
.build();
}
...omit other code...
};
}
@Bean
fun cacheFactory(
connectionFactory: RedisConnectionFactory,
objectMapper: ObjectMapper
): KCacheFactory {
return object: KCacheFactory {
override fun createObjectCache(type: ImmutableType): Cache<*, *>? =
...omit code...
// Map current object id to associated object id
// Applies to one-to-one and many-to-one associations
override fun createAssociatedIdCache(prop: ImmutableProp): Cache<*, *>? =
createPropCache(
prop,
Duration.ofMinutes(10),
Duration.ofHours(10)
)
// Map current object id to collection of associated object ids
// Applies to one-to-many and many-to-many associations
override fun createAssociatedIdListCache(prop: ImmutableProp): Cache<*, List<*>>? =
createPropCache(
prop,
Duration.ofMinutes(5),
Duration.ofHours(5)
)
private fun <K, V> createPropCache(prop: ImmutableProp, duration: Duration): Cache<K, V> =
ChainCacheBuilder<Any, Any>()
.add(
CaffeineValueBinder
.forProp(prop)
.maximumSize(512)
.duration(caffeineDuration)
.build()
)
.add(
RedisValueBinder
.forProp(prop)
.redis(connectionFactory)
.objectMapper(objectMapper)
.duration(redisDuration)
.build()
)
.build()
...omit other code...
}
}
Sorting Collection Associations
For collection type associations, if we use the field filter of object fetchers to implement association-level sorting, it will cause Jimmer to ignore association cache.
To make full use of association cache while keeping the sorting of the associated object collection returned by the object fetcher query controllable, you can specify the default sorting statically on the entity.
-
BookStore.books- Java
- Kotlin
BookStore.java@Entity
public interface BookStore {
@OneToMany(
mappedBy = "store",
orderedProps = {
@OrderedProp("name"),
@OrderedProp(value = "edition", desc = true)
}
)
List<Book> books();
...omit other code...
}BookStore.kt@Entity
interface BookStore {
@OneToMany(
mappedBy = "store",
orderedProps = {
@OrderedProp("name"),
@OrderedProp(value = "edition", desc = true)
}
)
val books : List<Book>
...omit other code...
} -
Book.authors- Java
- Kotlin
Book.java@Entity
public interface Book {
@ManyToMany(
orderedProps = {
@OrderedProp("firstName"),
@OrderedProp("lastName")
}
)
List<Author> authors();
...omit other code...
}Book.kt@Entity
interface Book {
@ManyToMany(
orderedProps = {
@OrderedProp("firstName"),
@OrderedProp("lastName")
}
)
val authors : List<Author>
...omit other code...
}
Usage
As mentioned at the beginning of this article, the examples here are based on the one-to-many association BookStore.books and the many-to-many association Book.authors.
One-to-Many: BookStore.books
- Java
- Kotlin
BookStoreTable table = Tables.BOOK_STORE_TABLE;
List<BookStore> stores = sqlClient
.createQuery(table)
.select(
table.fetch(
Fetchers.BOOK_STORE_FETCHER
.allScalarFields()
.books(
Fetchers.BOOK_FETCHER
.allScalarFields()
)
)
)
.execute();
System.out.println(stores);
val stores = sqlClient
.createQuery(BookStore::class) {
select(
table.fetchBy {
allScalarFields()
books {
allScalarFields()
}
}
)
}
.execute()
println(stores)
-
Step 1: Query aggregate root
First, query the aggregate root object, executing the following SQL:
select
tb_1_.ID,
tb_1_.NAME,
tb_1_.WEBSITE
from BOOK_STORE tb_1_The query in the code is implemented here to obtain some BookStore objects. Such objects obtained by direct user queries are called aggregate root objects.
cautionJimmer does not cache aggregate objects returned by user queries, because the consistency of such query results cannot be guaranteed.
Even if cache them at the cost of sacrificing consistency is required, it is a business need of the user rather than the framework.
-
Step 2: Convert current object id to associated object id via association cache
The above code will return a series of aggregate root objects. If using the official sample data in the database, it will return two aggregate root objects.
The object fetcher in the code contains the one-to-many association
BookStore.booksThe primary keys
IDof these 2 BOOK_STOREs are 1 and 2.Jimmer first looks up the data in Redis with keys
BookStore.books-1andBookStore.books-2.Suppose the data corresponding to these keys cannot be found in Redis:
127.0.0.1:6379> keys BookStore.books-*
(empty array)So the following SQL is executed to load data from the database:
select
tb_1_.STORE_ID,
tb_1_.ID,
tb_1_.NAME,
tb_1_.EDITION,
tb_1_.PRICE
from BOOK tb_1_
where
tb_1_.STORE_ID in (
? /* 1 */, ? /* 2 */
)
order by
tb_1_.NAME asc,
tb_1_.EDITION descJimmer will put the results of the query into Redis, so we can view this data in Redis:
127.0.0.1:6379> keys BookStore.books-*
1) "BookStore.books-2"
2) "BookStore.books-1"
127.0.0.1:6379> get BookStore.books-1
"[6,5,4,3,2,1,9,8,7]"
127.0.0.1:6379> get BookStore.books-2
"[12,11,10]"
127.0.0.1:6379>Thus, the two
BookStoreobjects can obtain the associated object id collections of their respective one-to-many associationsBookStore.books.Undoubtedly, before the data in Redis expires, executing the Java/Kotlin code above again will directly return the associated data from Redis without generating the second SQL statement.
-
Step 3: Convert associated object id to associated object via object cache
Such operations have been discussed in detail in Object Cache, so they are not repeated here. This article focuses on association cache.
cautionIn the cache configuration, if association cache is enabled for an association property but object cache is not enabled for its associated object type, an exception will be thrown.
Previously in Object Fetcher, we saw that Jimmer only needs one SQL statement to query all associated objects based on a batch of current objects, but here two SQL statements are needed, please view:
Finally, Jimmer concatenates the results of the two steps as the final data returned to the user:
[
{
"id":1,
"name":"O'REILLY",
"website":null,
"books":[
{
"id":6,
"name":"Effective TypeScript",
"edition":3,
"price":88
},
{
"id":5,
...omit...
},
{
"id":4,
...omit...
},
{
"id":3,
...omit...
},
{
"id":2,
...omit...
},
{
"id":1,
...omit...
},
{
"id":9,
...omit...
},
{
"id":8,
...omit...
},
{
"id":7,
...omit...
}
]
},
{
"id":2,
"name":"MANNING",
"website":null,
"books":[
{
"id":12,
"name":"GraphQL in Action",
"edition":3,
"price":80
},
{
"id":11,
...omit...
},
{
"id":10,
...omit...
}
]
}
]
Many-to-Many: Book.authors
- Java
- Kotlin
BookTable table = Tables.BOOK_TABLE;
List<Book> books = sqlClient
.createQuery(table)
.where(table.edition().eq(1))
.select(
table.fetch(
Fetchers.BOOK_FETCHER
.allScalarFields()
.authors(
Fetchers.AUTHOR_FETCHER
.allScalarFields()
)
)
)
.execute();
System.out.println(books);
val books = sqlClient
.createQuery(Book::class) {
where(table.edition eq 1)
select(
table.fetchBy {
allScalarFields()
authors {
allScalarFields()
}
}
)
}
.execute()
println(books)
-
Step 1: Query aggregate root
First, query the aggregate root object, executing the following SQL:
select
tb_1_.ID,
tb_1_.NAME,
tb_1_.EDITION,
tb_1_.PRICE
from BOOK tb_1_
where
tb_1_.EDITION = ? /* 1 */The query in the code is implemented here to obtain some Book objects. Such objects obtained by direct user queries are called aggregate root objects.
cautionJimmer does not cache aggregate objects returned by user queries, because the consistency of such query results cannot be guaranteed.
Even if cache them at the cost of sacrificing consistency is required, it is a business need of the user rather than the framework.
-
Step 2: Convert current object id to associated object ids via association cache
The above code will return a series of aggregate root objects. If using the official sample data in the database, it will return 4 aggregate root objects.
The object fetcher in the code contains the many-to-many association
Book.authorsThe primary keys
IDof these 4 BOOKs are 1, 4, 7 and 10.Jimmer first looks up the data in Redis with keys
Book.authors-1,Book.authors-4,Book.authors-7andBook.authors-10.Suppose the data corresponding to these keys cannot be found in Redis:
127.0.0.1:6379> keys Book.authors-*
(empty array)So the following SQL is executed to load data from the database:
select
tb_1_.BOOK_ID,
tb_1_.AUTHOR_ID
from BOOK_AUTHOR_MAPPING tb_1_
inner join AUTHOR tb_3_
on tb_1_.AUTHOR_ID = tb_3_.ID
where
tb_1_.BOOK_ID in (
? /* 1 */, ? /* 4 */, ? /* 7 */, ? /* 10 */
)
order by
tb_3_.FIRST_NAME asc,
tb_3_.LAST_NAME ascnoteIf no default sort is specified for the association property
Book.authorsvia@ManyToMany.orderedProps, thejoinhere will not appear.Jimmer will put the results of the query into Redis, so we can view this data in Redis:
127.0.0.1:6379> keys Book.authors-*
1) "Book.authors-4"
2) "Book.authors-1"
3) "Book.authors-10"
4) "Book.authors-7"
127.0.0.1:6379> get Book.authors-1
"[2,1]"
127.0.0.1:6379> get Book.authors-4
"[3]"
127.0.0.1:6379> get Book.authors-7
"[4]"
127.0.0.1:6379> get Book.authors-10
"[5]"
127.0.0.1:6379>Thus, we have obtained the associated object id collections that the 4
Bookobjects can get through their respective many-to-many associationBook.authors.Undoubtedly, before the data in Redis expires, executing the Java/Kotlin code above again will directly return the associated data from Redis without generating the second SQL statement.
-
Step 3: Convert associated object id to associated object via object cache
Such operations have been discussed in detail in Object Cache, so they are not repeated here. This article focuses on association cache.
cautionIn the cache configuration, if association cache is enabled for an association property but object cache is not enabled for its associated object type, an exception will be thrown.
Previously in Object Fetcher, we saw that Jimmer only needs one SQL statement to query all associated objects based on a batch of current objects, but here two SQL statements are needed, please view:
Finally, Jimmer concatenates the 3 steps results as the final data returned to the user:
[
{
"id": 1,
"name": "Learning GraphQL",
"edition": 1,
"price": 51,
"authors": [
{
"id": 2,
"firstName": "Alex",
"lastName": "Banks",
"gender": "MALE"
},
{
"id": 1,
"firstName": "Eve",
"lastName": "Procello",
"gender": "FEMALE"
}
]
},
{
"id": 4,
"name": "Effective TypeScript",
"edition": 1,
"price": 73,
"authors": [...omit...]
},
{
"id": 7,
"name": "Programming TypeScript",
"edition": 1,
"price": 47.5,
"authors": [...omit...]
},
{
"id": 10,
"name": "GraphQL in Action",
"edition": 1,
"price": 80,
"authors": [...omit...]
}
]
Cache Invalidation
To use Jimmer's automatic cache invalidation, triggers need to be enabled first.
One-to-Many: BookStore.books
Modify the foreign key STORE_ID of the BOOK table, Jimmer automatically deletes the many-to-one association cache Book.store and the one-to-many association cache BookStore.books.
-
If BinLog trigger is enabled, modifying the database by any means can lead to Jimmer's cache consistency intervention. For example, directly execute the following SQL in the SQL IDE:
update BOOK
/* Old value: 1, New value: 2 */
set STORE_ID = 2
where ID = 7; -
If only Transaction trigger is enabled, Jimmer's API must be used to modify the database:
- Java
- Kotlin
BookTable table = Tables.BOOK_TABLE;
sqlClient
.createUpdate(table)
// Old value: 1L, New value: 2L
.set(table.store().id, 2L)
.where(table.id().eq(7L))
.execute();sqlClient
.createUpdate(Book::class) {
// Old value: 1L, New value: 2L
set(table.store.id, 2L)
where(table.id eq 7L)
}
.execute()
Regardless of which way above is used to modify the data, you will see the following log output:
Delete data from redis: [Book-7]
Delete data from redis: [Book.store-7] ❶
Delete data from redis: [BookStore.books-1] ❷
Delete data from redis: [BookStore.books-2] ❸
- ❶ For the Book object with id
7, its many-to-one association cacheBook.storeis deleted. - ❷ For the BookStore object with id
1(old value before modification), its one-to-many association cacheBookStore.booksis deleted. - ❸ For the BookStore object with id
2(new value before modification), its one-to-many association cacheBookStore.booksis deleted.
Many-to-Many: Book.authors
Inserting data into the join table BOOK_AUTHOR_MAPPING automatically deletes the many-to-many association caches Book.authors and Author.books.
Deleting data from the join table can achieve the same effect. Here insertion is used to demonstrate the effect.
-
If BinLog trigger is enabled, modifying the database by any means can lead to Jimmer's cache consistency intervention. For example, directly execute the following SQL in the SQL IDE:
insert into
BOOK_AUTHOR_MAPPING(BOOK_ID, AUTHOR_ID)
values(10, 3); -
If only Transaction trigger is enabled, Jimmer's API must be used to modify the database:
- Java
- Kotlin
sqlClient
.getAssociations(BookProps.AUTHORS)
.save(10L, 3L);sqlClient
.getAssociations(Book::authors)
.save(10L, 3L);
Regardless of which way above is used to modify the data, you will see the following log output:
Delete data from redis: [Book.authors-10] ❶
Delete data from redis: [Author.books-3] ❷
- ❶ For the Book object with id
10, its many-to-many association cacheBook.authorsis deleted. - ❷ For the Author object with id
3, its many-to-many association cacheAuthor.booksis deleted.
Notes on Logical Deletion
If associated objects support logical deletion, association caching is still supported by default.