基本用法
简介
保存指令允许开发人员保存任意形状的数据结构,而非保存简单的对象。
在默认情况下,即在AssociatedSaveMode为REPLACE情况下,Jimmer会用被保存结构去全量替换数据库中已有的数据结构,如图所示:
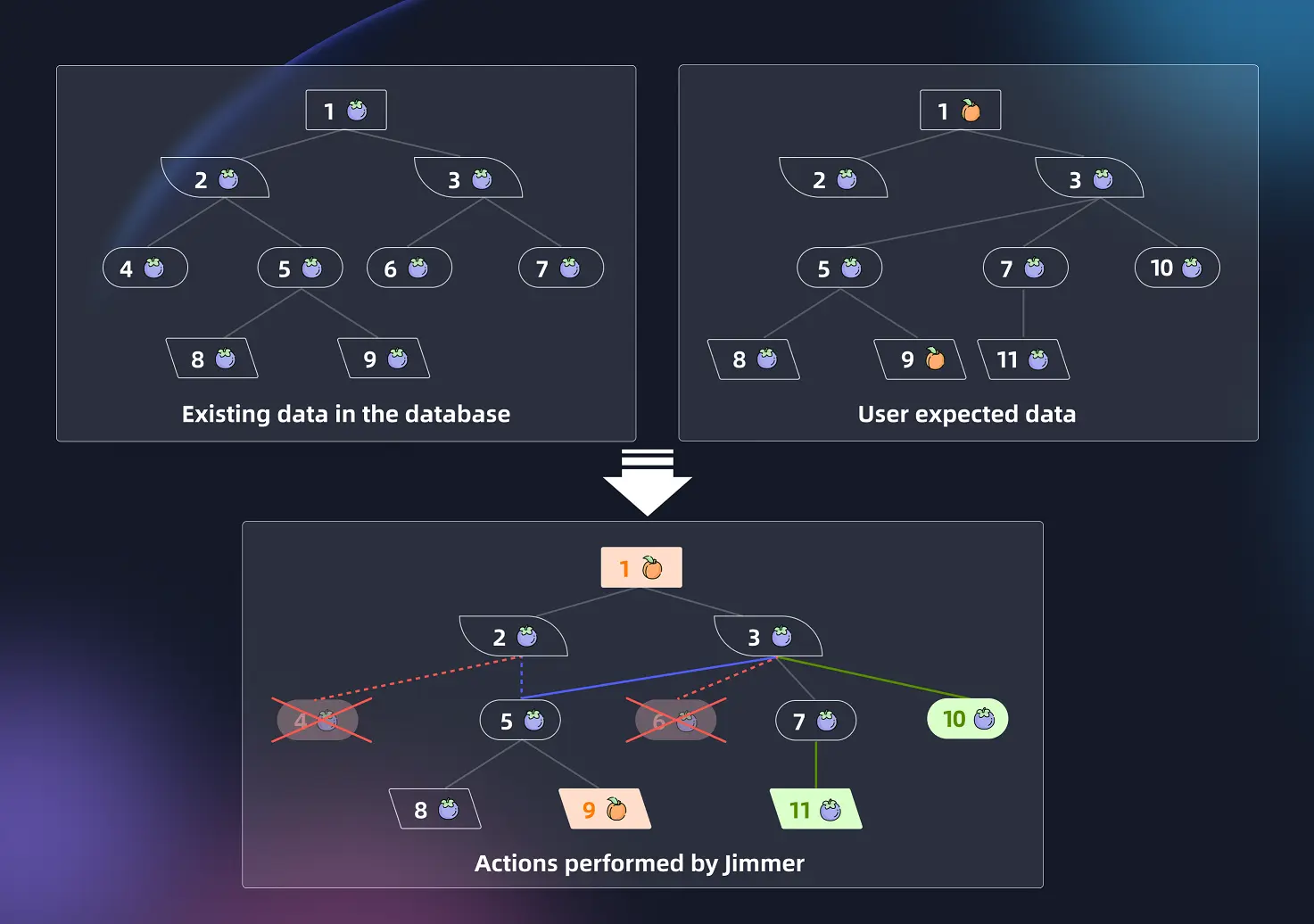
右上角: 用户传入一个任意形状的数据结构,让Jimmer写入数据库。
左上角: 从数据库中查询已有的数据结构,用于和用户传入的新数据结构对比。
用户传入什么形状的数据结构,就从数据查询什么形状的数据结构,新旧数据结构的形状完全一致。所以,查询成本和对比成本由用户传入的数据结构的复杂度决定。
下方: 对比新旧数据结构,找出DIFF并执行相应的SQL操作,让新旧数据一致:
- 橙色部分:对于在新旧数据结构中存在的实体对象,如果某些标量属性发生变化,修改数据
- 蓝色部分:对于在新旧数据结构中存在的实体对象,如果某些关联发生变化,修改关联
- 绿色部分:对于在新数据结构中存在但在旧数据结构中不存在实体对象,插入数据并建立关联
- 红色部分:对于在旧数据结构中存在但在新数据结构中不存在实体对象,对此对象进行脱钩,清除关联并有可能删除数据
和其他ORM不同,Jimmer无需在实体模型上描述数据如何保存
- 某些标量属性是否需要被保存以JPA为例,通过Column.insertable和Column.updatable控制。
- 某些关联属性是否需要被保存
Jimmer采用完全不同的策略,其实体对象并非POJO,可以灵活地控制数据结构的形状。
即,实体对象具备动态性,不为实体对象指定某个属性和将实体的某个属性指定为null,是完全不同的事情。
对于任何一个实体对象而言,Jimmer只会保存被指定的属性,而忽略未指定的属性。
因此,Jimmer无需在实体建模时考虑数据的保存行为,而是在运行时通过被保存的数据结构自身来描述期望的行为,具备绝对的灵活性。
1. 单个实体对象的灵活性
1.1. 灵活控制简单属性是否被修改
让我们先来看Jimmer如何区分如下两种需求
-
不更新对象的某个属性
-
将对象的某个属性更新为null
对于传统的静态语言ORM而言,这是一个非常棘手的问题。但是Jimmer可以轻松区分这两种不同的行为。
1.1.1. 不更新对象的某个属性
- Java
- Kotlin
sqlClient.update(
Immutables.createBook(draft -> {
draft.setId(8L);
draft.setPrice(new BigDecimal("33.9"));
// 并未指定`store`或`storeId属性`
})
);
sqlClient.update(
Book {
id = 8L
price = BigDecimal("33.9")
// 并未指定`store`或`storeId属性`
}
);
生成如下SQL
update BOOK
set
PRICE = ? /* 33.9 */
where
ID = ? /* 8 */
可见,只修改被指定的字段PRICE,并未修改其他未指定的字段 (包括STORE_ID)。
1.1.2. 将对象的某个属性更新为null
- Java
- Kotlin
sqlClient.update(
Immutables.createBook(draft -> {
draft.setId(8L);
draft.setPrice(BigDecimal("33.9"))
draft.setStore(null);
// 也可写作`draft.setStoreId(null)`
})
);
sqlClient.update(
Book {
id = 8L
price = BigDecimal("33.9")
store = null
// 也可写作`storeId = null`
}
);
生成如下SQL
update BOOK
set
PRICE = ? /* 33.9 */
STORE_ID = ? /* <null: long> */
where
ID = ? /* 8 */
1.2. 用不完整对象避免先查后改
在实际业务项目中,常常遇一个需求:更新实体的部分属性,而非所有属性。
然而,在传统ORM的开发模式中,为了省事,开发人员很少使用ORM的update语句,更多地选择先查询对象,再修改,最后保存。以JPA为例:
EntityManager entityManager = ...从当前事务上下文中获取JPA会话对象,略...
Book book = entityManager.find(Book.class, 8L);
book.setStore(null); // JPA中实体是可变的,将关联修改为null
// 这里调用merge仅为了清晰,可以不调,因为事务提交时JPA必然修改数据库
entityManager.merge(book);
其实,除了要将Book.store修改为null外,其实这个场景对对象的其他属性完全不感兴趣。
很显然,这是一种浪费。如果实体对象具备很多属性,会更加明显。
Jimmer的实体对象并不要求制定所有属性,即,Jimmer支持不完整对象。
因此,你可以凭空捏造一个不完整的Book对象,仅指定其id属性和store属性,并让Jimmer直接更新即可。
- Java
- Kotlin
sqlClient.update(
Immutables.createBook(draft -> {
draft.setId(8L);
draft.setStore(null);
})
);
sqlClient.update(
Book {
id = 8L
store = null
}
);
生成如下SQL
update BOOK
set
STORE_ID = ? /* <null: long> */
where
ID = ? /* 8 */
2. 关联属性的灵活性
通过单个对象的案例,我们对保存指令的灵活性有了基本的了解。
接下来,介绍保存指令对关联属性的控制能力。
2.1. 是否级联保存关联属性
在大部分ORM中,通过关联属性的casscade配置来决定在保存某个对象时是否一起保存关联对象。
以JPA为例,可以通过4个配置来实现这种配置:
然而,如何抉择这些配置是痛苦的,无论如何配置,都是在实体建模阶段固化模型的行为模式,实体设计和业务需求耦合过于紧密。
Jimmer没有类似的配置,具体行为取决于被保存的数据结构自身的格式。例如
-
只保存
BookStore对象- Java
- Kotlin
BookStore store = Immutables.createBookStore(draft -> {
draft.setName("AMAZON");
draft.setWebsite("https://www.amazon.com");
});
sqlClient.save(store);val store = BookStore {
name = "AMAZON"
website = "https://www.amazon.com"
}
sqlClient.save(store) -
保存
BookStore对象时级联保持相关的Book对象- Java
- Kotlin
BookStore store = Immutables.createBookStore(draft -> {
draft.setName("AMAZON");
draft.setWebsite("https://www.amazon.com");
draft.addIntoBooks(book -> {
book.setName("C++ Primer");
book.setEdition(5);
book.setPrice(new BigDecimal("44.02"));
});
draft.addIntoBooks(book -> {
book.setName("Programming RUST");
book.setEdition(1);
book.setPrice(new BigDecimal("71.99"));
});
});
sqlClient.save(store);val store = BookStore {
name = "AMAZON"
website = "https://www.amazon.com"
books().addBy {
name = "C++ Primer"
edition = 5
price = BigDecimal("44.02")
}
books().addBy {
name = "Programming RUST"
edition = 1
price = BigDecimal("71.99")
}
}
sqlClient.save(store)
2.2. 双向关联的对称性
ORM具备一个重要的概念,双向关联。以本教程为例,Book.authors和Author.books就互为双向关联。
无论是JPA还是Jimmer,双向关联的两端都分为主动方和从动方
- 主动方:关联注解的
mappedBy属性未指定 - 从动方:关联注解的
mappedBy属性被指定
但是,Jimmer和JPA存在巨大成差异
-
在JPA中,必须让主动方的对象充当上级对象,让从动方对象充当关联对象。否则,修改行为无效。
为JPA双向关联抉择主动方同样非常痛苦,本质上也是在实体建模阶段固化模型的行为模式,实体设计和业务需求耦合过于紧密
-
在Jimmer中,无论如何抉择主动方和从动方,对保存指令没有任何影响。
- 如果双向关联的主动方抉择被Jimmer限制 (例如, 基于一对多和多对一关联构建双向关联时, Jimmer规定一对多关联必须是从动方),就按照Jimmer的要求定义双向关联
- 否则,按照自己的意愿随心所欲地定义双向关联
在Jimmer中,你可以按自己的意愿随心所欲地操作双向关联,例如
-
保存
Book对象,并修改和Author之间的关联,即,通过Book.authors实现关联修改- Java
- Kotlin
Book book = Immutables.createBook(draft -> {
draft.setName("C++ Primer");
draft.setEdition(5);
draft.setPrice(new BigDecimal("44.02"));
draft.addIntoAuthors(author -> author.setId(10L));
draft.addIntoAuthors(author -> author.setId(11L));
draft.addIntoAuthors(author -> author.setId(12L));
})
sqlClient.save(book);val book = Book {
name = "C++ Primer"
edition = 5
price = BigDecimal("44.02")
authors().addBy { id = 10L }
authors().addBy { id = 11L }
authors().addBy { id = 12L }
}
sqlClient.save(book); -
保存
Author对象,并修改和Book之间的关联,即,通过Author.books实现关联修改- Java
- Kotlin
Author author = Immutables.createAuthor(draft -> {
draft.setFirstName("Stanley");
draft.setLastName("Lippman");
draft.setGender(Gender.MALE);
draft.addIntoBooks(book -> book.setId(40L));
draft.addIntoBooks(book -> book.setId(41L));
draft.addIntoBooks(book -> book.setId(42L));
draft.addIntoBooks(book -> book.setId(43L));
draft.addIntoBooks(book -> book.setId(44L));
draft.addIntoBooks(book -> book.setId(45L));
});
sqlClient.save(author);val author = Author {
firstName = "Stanley"
lastName = "Lippman"
gender = Gender.MALE
books().addBy { id = 40L }
books().addBy { id = 41 }
books().addBy { id = 42L }
books().addBy { id = 43L }
books().addBy { id = 44L }
books().addBy { id = 45L }
}
sqlClient.save(author)
3. 自己决定功能复杂度
保存指令非常灵活,可能体现为非常强大的高级功能,也可能体现为非常简单的基础功能。这一切由你决定。
在日常项目开发中,有两种截然不同的需求
-
面向复杂表单的全量数据替换
-
面向简单数据的增量修改
就开发任务的复杂度而言,一个非常复杂,一个非常简单。但是,Jimmer对它们一视同仁,一律给予快速实现。
3.1. 面向复杂表单的全量数据替换
复杂表单,通常包含关联关系 (例如订单和订单明细),甚至可能包括递归数据结构 (例如, UI拖拉拽系统,UML绘图工具)。
无论多么复杂,把这个数据结构视为一个整体,一句话保存即可。
为了让例子具备代表性,我们在这里提前使用还未讲解的Input DTO,虽然相关内容目前暂时没有讲解,但读者猜到用途不难。
使用Jimmer附带的DTO语言定义一个叫做BookStoreInput的类型。
export com.yourcompany.yourproject.BookStore
-> pacage com.yourcompany.yourproject.dto;
input BookStoreInput {
#allScalars
books {
#allScalars
id(authors) as authorIds
}
}
经Jimmer编译后,自动一个名称为BookStoreInput的Java或Kotlin类。
BookStoreInput和POJO类似,是高度静态的类型,用于约定、限制并接受客户端提交的HTTP请求内容。
同时,该类可以自动转化为BookStore实体对象和相关关联对象。
- Java
- Kotlin
@PutMapping("/store")
public void saveBookStore(
@RequestBody BookStoreInput input
) {
sqlClient.save(input);
}
@PutMapping("/store")
fun saveBookStore(
@RequestBody input: BookStoreInput
) {
sqlClient.save(input);
}
这里,sqlClient.save(input)先把input DTO转化为BookStore实体对象和相关关联对象,然后直接保存整个数据结构,完成复杂表单数据的全量替换。
保存指令会递归地处理整个数据结构中的各级对象,对比被保存的数据结构和数据库中的现有数据结构,找出不一致的部分并修改。
然而,无论这个过程的内部细节多么复杂,对用户透明。
3.2. 面向简单数据的增量修改
现在,我们来实现一个非常简单的需求,为书店增加一本书。
- Java
- Kotlin
@PutMapping("/store/{storeId}/books/{bookId}")
public void addBook(
@PathVariable long storeId,
@PathVariable long bookId
) {
sqlClient.update(
Immutables.createBook(
draft.setId(bookId);
draft.setStoreId(storeId);
)
)
}
@PutMapping("/store/{storeId}/books/{bookId}")
fun addBook(
@PathVariable storeId: Long,
@PathVariable bookId: Long
) {
sqlClient.update(
Book {
id = bookId
storeId = storeId
}
)
}
这是一个非常简单的例子,而前一个例子则完全不同,保存例子完成了非常复杂的工作。
保存指令既可体现为非常强大的高级功能,也可体现为非常简单的基础功能,一切皆有可能,这完全取决于你如何使用。
安全性
保存指令为数据保存业务带来了绝对的灵活性,然而,过于强大的灵活性也往往意味着对安全性的破坏。
即,客户端可以随心所欲地向服务端写入任意复杂的数据结构,哪怕这远远超出它的权限范围。
为此,Jimmer采用分而治之的思想
-
保存指令本身做为底层支持,接受Jimmer的动态实体,提供绝对的灵活��性和无限的可能性。
-
引入InputDTO,自动生成类似于POJO的静态类型,规范并限制客户端的行为,并负责接受请求数据。最终自动转化为实体对象树,由保存指令处理。