基本概念
概念
截止目前为止,我们所介绍的缓存都是单视图缓存,所有客户端都会看到相同的缓存数据。
然而,很多时候,不同的客户端会看到不同的持久化数据,这往往是因为权限系统导致的。
既然不同的客户端会看到不同的持久化数据,我们自然也期望不同客户端能看到不同的缓存数据。
多视图缓存很好地解决这个问题,让不同的客户端看到不同的缓存,即缓存为不同的客户端提供了不同的视图。
| 单视图缓存 | 多视图缓存 | |
|---|---|---|
| 对象缓存 | 对象缓存 | NA |
| 关联缓存 | 单视图关联缓存 | 多视图关联缓存 |
| 计算缓存 | 单视图计算缓存 | 多视图计算缓存 |
我们可以把关联缓存和计算缓存统称为属性缓存
因此,这个的表格也可被解释为属性缓存可以被多视图化。
场景
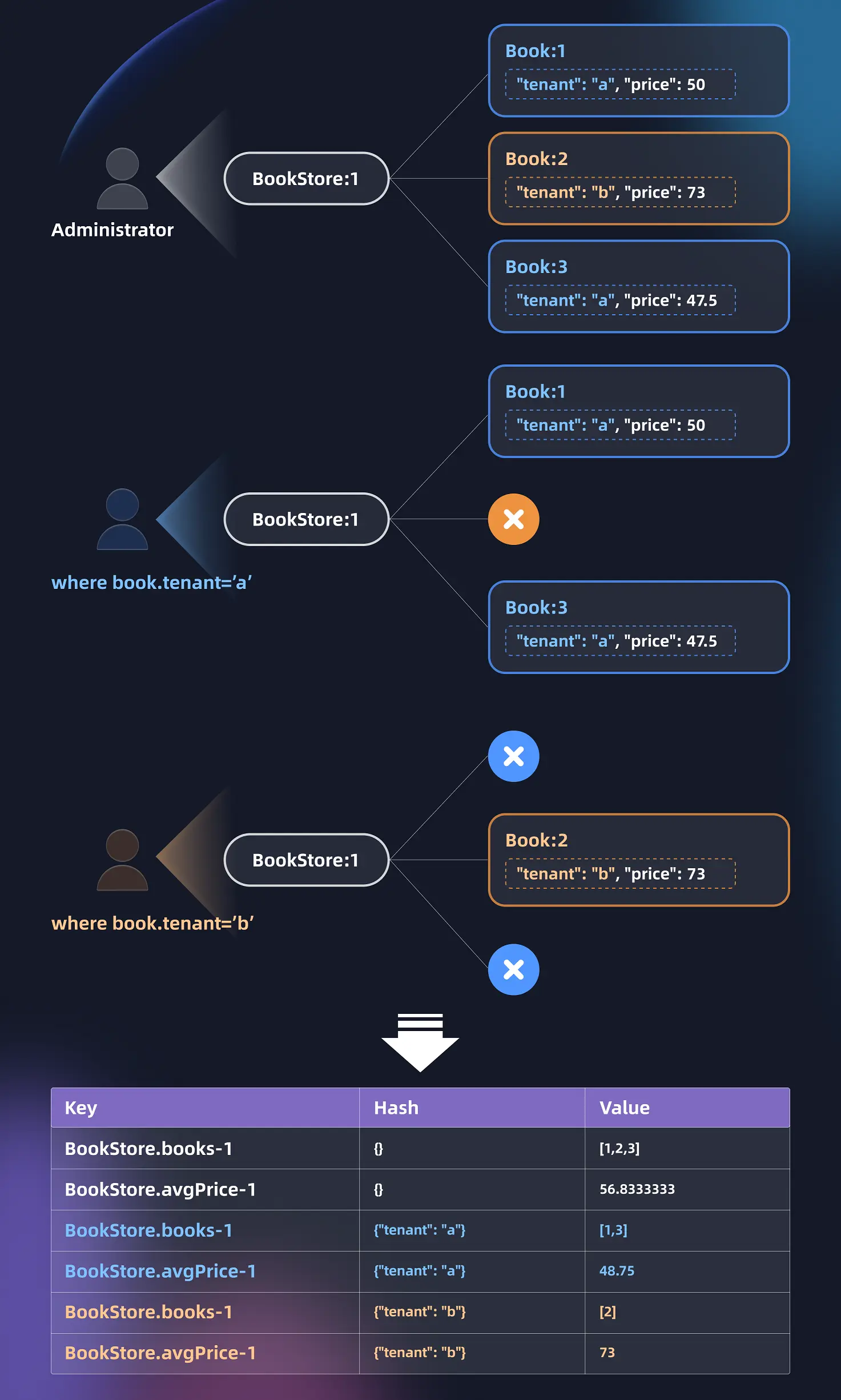
多视图缓存由用户自定义全局过滤器导致。
比如,如果为Book添加全局过滤器,那么如下这些属性:
-
以
Book作为目标类型的关联属性。比如,BookStore.books、Author.books -
依赖于上述关联属性的计算属性。比如,
BookStore.avgPrice、BookStore.newestBooks(文档没提及newestBook,可参见例子)
都会对过滤器敏感,即不同的过滤条件会导致不同的客户端看到不同的数据。
这些对过滤器敏感的属性,要么不支持缓存,要么就支持多视角缓存。如果为其配置单视图缓存,将被视为无效操作,缓存配置会被忽略。
然而,无需担心,Jimmer会告诉开发人员为什么缓存未生效。
SubKey
SubKey是多视图缓存的重要概念,也是后续文档所需的前提概念。
让我们先来看看单视图缓存的结构
| Key | Value |
|---|---|
| Book-10 | {"id":10,"name":"GraphQL in Action",...} |
| Book.authors-1 | [1,2] |
| BookStore.avgPrice-2 | 80.333333 |
这里,我们列举了对象缓存、关联缓存和计算缓存。 虽然缓存类型不尽相同,但缓存结构都是统一的简单KV结构。
再让我们来看看多视图缓存的例子
| Key | SubKey | Value |
|---|---|---|
| BookStore.books-1 | {} | [6,5,4,3,2,1,9,8,7] |
| {"tenant":"a"} | [5,3,1,9,7] | |
| {"tenant":"b"} | [6,4,2,8] | |
| {"module":"x"} | [6,5,3,2,9,8] | |
| {"module":"x","tenant":"a"} | [5,3,9] | |
| {"module":"x","tenant":"b"} | [6,2,8] | |
| {"module":"y"} | [4,1,7] | |
| {"module":"y","tenant":"a"} | [1,7] | |
| {"module":"y","tenant":"b"} | [4] | |
| BookStore.books-2 | {} | [12,11,10] |
| {"tenant":"a"} | [11] | |
| {"tenant":"b"} | [12,10] | |
| {"module":"x"} | [12,11] | |
| {"module":"x","tenant":"a"} | [11] | |
| {"module":"x","tenant":"b"} | [12] | |
| {} | [10] | |
| {"tenant":"a"} | [] | |
| {"tenant":"b"} | [10] |
多视图缓存不再是简单的KV结构,而是嵌套的两级KV结构。
对于Redis而言,这种结构就是Redis Hashes。
此时表格中的SubKey就是Redis中的Hash Key
很明显,相比于单视图缓存而言,多视图缓存按照SubKey对数据进行了更细的分化,让不同的客户端看到不同的数据。
-
Key
多视图缓存中的Key,和单视图缓存中的Key无异,表示特定的实体属性,由Jimmer自定决定
-
SubKey
多视图缓存的关键特性,权限系统让不同的客户端具备不同的SubKey,最终从缓存中提取到不同的数据
信息在Jimmer中,SubKey一定是
java.util.SortedMap<String, Object>经过JSON序列化后的字符串。此
SortedMap必须采用默认的排序规则,不得自定义Comparator。这点非常重要。比如,SubKey只可能是
{"module":"x","tenant":"a"},而不可能与之不同但等价的{"tenant":"a", "module":"x"}。 这样,多视图缓存保证了其内部没有冗余的信息。
多视图缓存只针对属性缓存,即关联缓存和计算缓存。所以,关联属性和复杂计算属性必须为其多视图缓存指定SubKey
关联属性的SubKey
对于关联属性而言,缓存的多视图化必然是因其关联实体被用户自定义全局过滤器影响导致。
支持多视图缓存的全局过滤器仅仅实现Filter/KFilter接口是不够的,必须实现CacheableFilter/KCacheableFilter接口
- Java
- Kotlin
package org.babyfish.jimmer.sql.filter;
public interface CacheableFilter<P extends Props> extends Filter<P> {
SortedMap<String, Object> getParameters();
...省略其他代码...
}
package org.babyfish.jimmer.sql.kt.filter
interface KCacheableFilter<E: Any> : KFilter<E> {
fun getParameters(): SortedMap<String, Any>?
...省略其他代码...
}
用户需要实现getParameters()方法,为SubKey贡献一部分信息。
当关联实体受多个CacheableFilter/KCacheableFilter影响时,每个过滤器对象的getParameters()方法返回的数据合并在一起,作为SubKey。
复杂计算属性的SubKey
实现复杂计算属性需实现TransientResolver/KTransientResolver接口
- Java
- Kotlin
package org.babyfish.jimmer.sql;
import org.babyfish.jimmer.lang.Ref;
import java.util.SortedMap;
public interface TransientResolver<ID, V> {
default Ref<SortedMap<String, Object>> getParameterMapRef() {
return Ref.empty();
}
...省略其他代码...
}
package org.babyfish.jimmer.sql.kt
import org.babyfish.jimmer.lang.Ref
interface KTransientResolver<ID: Any, V> : TransientResolver<ID, V> {
override fun getParameterMapRef(): Ref<SortedMap<String, Any>?>? =
Ref.empty()
...省略其他代码...
}
该方法返回SortedMap的Ref包装器
-
如果
Ref本身为null,表示获取SubKey遇到困难,无法为计算属性应用多视图缓存信息这种情况下,Jimmer会告诉开发人员为什么缓存未生效
-
否则,
Ref内部的value就表示当前计算属性的SubKey
Jimmer在维护缓存一致性时,会自动删除失效的缓存数据。
多视图的缓存项总是按照Key进行整体删除,不会按照Key + SubKey进行局部删除,在最大程度上保证多视图缓存的相对简单性。